

The code for this article is on GitHub: https://github.com/Vaultspeed/generic-fmc-integrations/tree/main/snowflake_tasks
NOTE: This example does not support Object-specific loading window.
In addition to generating the DDL code for the deployment of Data Vault models and the ETL code to load these models, VaultSpeed has long offered out-of-the-box support for orchestration tools such as Airflow and Azure Data Factory. Now, with the introduction of the Generic FMC option for orchestration, VaultSpeed can generate the logic needed to create orchestration jobs to run on virtually any orchestration platform.
One of the first options we used to test the Generic FMC was Snowflake Tasks. This was an exciting option because it allows a customer to deploy all the VaultSpeed code components to a single, solid, and highly performant cloud data warehouse. In this post, I will walk you through one option for deploying and running VaultSpeed's load orchestration in Snowflake Tasks using just SQL.
The Model
Using my sample SpeedShop schemas in my Snowflake landing database as my sources, I created my Data Vault model. Then I generated and deployed the DDL and ETL to my target Snowflake data warehouse.
Next, I generated the FMC workflow for the initial load of my Data Vault, making sure my system parameter FMC_TYPE was set to the option "generic." Be sure to generate a new release of the data vault after you have set the FMC_TYPE = “generic”:

The Snowflake SQL Objects
After creating the FMC, I was ready to set up my Snowflake schema with the objects I needed to (1) Assist with executing the load stored procedures generated in VaultSpeed and (2) create the Snowflake Task DAG. These objects are:
A database schema named "TASKER"
CREATE OR REPLACE SCHEMA TASKER;A table named "JSON_MAPPING" with a variant column to store the JSON. (Later in the post, you will see how I queried it to flatten the JSON mappings into records we can use to build the DAG)
CREATE OR REPLACE TABLE TASKER.TASK_MAPPING (ID NUMBER(38,0) autoincrement, JSON_MAPPING VARIANT );A sequence object named "FMC_SEQ" for generating a load cycle id for each DAG execution.
CREATE OR REPLACE SEQUENCE TASKER.FMC_SEQ START = 1 INCREMENT = 1;A stored procedure named "GET_LOAD_CYCLE_ID()" for capturing the load sequence as a variable that can be passed through the DAG. (OK, this is almost all SQL. This proc was the only one that needed JavaScript.)
CREATE OR REPLACE PROCEDURE TASKER.GET_LOAD_CYCLE_ID()
RETURNS VARCHAR(16777216)
LANGUAGE JAVASCRIPT
EXECUTE AS CALLER
AS '
var LoadCycleIdRslt=snowflake.execute({ sqlText: " SELECT TASKER.FMC_SEQ.NEXTVAL"});
LoadCycleIdRslt.next();
var LoadCycleId = LoadCycleIdRslt.getColumnValue(1);
var lci_str="''"+LoadCycleId+"''";
var sql_str="CALL SYSTEM$SET_RETURN_VALUE("+lci_str+")";
var res = snowflake.execute({sqlText:sql_str});
return "SUCCESS";
';A stored procedure named “RUN_MAPPING_PROC()” for running the load procedures with error handling. The catch block executes the failure task at the end of the DAG.
CREATE OR REPLACE PROCEDURE TASKER.RUN_MAPPING_PROC("PROC_NAME" VARCHAR(50), "LOAD_CYCLE_ID" VARCHAR(16777216))
RETURNS VARCHAR(16777216)
LANGUAGE JAVASCRIPT
EXECUTE AS OWNER
AS '
var call_sp_sql = "CALL "+PROC_NAME;
try {
snowflake.execute( {sqlText: call_sp_sql} );
result = "SUCCESS";
}
catch (err) {
result = "Failed: Code: " + err.code + "\\\\n State: " + err.state;
result += "\\\\n Message: " + err.message;
result += "\\\\nStack Trace:\\\\n" + err.stackTraceTxt;
}
return result;
';A stored procedure named "CREATE_VS_FMC()". This is the main procedure that builds and deploys the tasks into a DAG: convert the JSON output to a Snowflake DAG. This is a lengthy stored procedure. Refer to the GitHub code repository for the entire deployment script for all 6 objects.
CREATE OR REPLACE PROCEDURE TASKER.CREATE_VS_FMC("VAR_WH" VARCHAR(255), "TASK_SCHEMA" VARCHAR(255), "DAG_NAME" VARCHAR(240), "LOAD_SCHED" VARCHAR(100))
RETURNS VARCHAR(16777216)
LANGUAGE SQL
EXECUTE AS OWNER
AS '
DECLARE var_job VARCHAR(255) default ''''; -- assigned task name derived from procedure name
var_proc VARCHAR(255)default ''''; -- task stored procedure name
var_dep VARCHAR(255) default ''''; -- task dependency name
var_seq INT default 0; -- load group sequence number
dep_arr ARRAY default ARRAY_CONSTRUCT(); -- array for dependencies
dep_counter INTEGER default 0; -- dependency counter
dep_list VARCHAR(10000) default ''''; -- dependency list for AFTER clause in CREATE TASK statement
dep_last_task VARCHAR(255) default ''''; -- last dependency (needed to pass load cycle id to last task in dag)
proc_schema VARCHAR(255) default ''''; -- schema containing load procedures
task_name VARCHAR(255) default ''''; -- name of the task in the TASK CREATE statement
task_sql VARCHAR(10000) default ''''; -- single create task sql statement
var_sql VARCHAR(150000) default ''''; -- string containing sql statement to be executed
max_layer INT default 0; -- Number of load layers in FMC workflow
task_counter INT default 0; -- counter tallying # of tasks
BEGIN
-- Create initial task for getting load cycle id
var_sql := ''CREATE OR REPLACE TASK EXEC_''||UPPER(dag_name)||'' WAREHOUSE = ''||var_wh||'' SCHEDULE = ''''''||load_sched||'''''' AS CALL ''||UPPER(task_schema)||''.GET_LOAD_CYCLE_ID();'';
EXECUTE IMMEDIATE var_sql;
task_counter := task_counter + 1;
-- Create temp table for task mappings (jobs)
CREATE OR REPLACE TEMP TABLE JOBS (SEQ INT, JOB VARCHAR(255), PROC_SCHEMA VARCHAR(255), DEPENDENCY VARCHAR(255));
-- Insert task mappings into JSON temp table, assigning a number sequence to each load layer.
INSERT INTO JOBS (SEQ, JOB, PROC_SCHEMA, DEPENDENCY)
WITH JD AS (
SELECT j.KEY AS JOB
,j.VALUE:map_schema::string AS PROC_SCHEMA
,d.VALUE::string AS DEPENDENCY
FROM TASK_MAPPING,
LATERAL FLATTEN(input=> JSON_MAPPING) j,
LATERAL FLATTEN(input=> j.VALUE:dependencies, outer=> true) d
)
,"00" AS (
SELECT 0 AS SEQ, JOB, PROC_SCHEMA, DEPENDENCY FROM JD WHERE DEPENDENCY is null
)
,"01" AS (
SELECT 1 AS SEQ, JOB, PROC_SCHEMA, DEPENDENCY FROM JD WHERE DEPENDENCY IN (SELECT JOB FROM "00")
)
,"02" AS (
SELECT 2 AS SEQ, JOB, PROC_SCHEMA, DEPENDENCY FROM JD WHERE DEPENDENCY IN (SELECT JOB FROM "01")
)
,"03" AS (
SELECT 3 AS SEQ, JOB, PROC_SCHEMA, DEPENDENCY FROM JD WHERE DEPENDENCY IN (SELECT JOB FROM "02")
)
,"04" AS (
SELECT 4 AS SEQ, JOB, PROC_SCHEMA, DEPENDENCY FROM JD WHERE DEPENDENCY IN (SELECT JOB FROM "03")
)
,"05" AS (
SELECT 5 AS SEQ, JOB, PROC_SCHEMA, DEPENDENCY FROM JD WHERE DEPENDENCY IN (SELECT JOB FROM "04")
)
,"06" AS (
SELECT 6 AS SEQ, JOB, PROC_SCHEMA, DEPENDENCY FROM JD WHERE DEPENDENCY IN (SELECT JOB FROM "05")
)
SELECT SEQ, JOB, PROC_SCHEMA, DEPENDENCY FROM "00"
UNION ALL
SELECT SEQ, JOB, PROC_SCHEMA, DEPENDENCY FROM "01"
UNION ALL
SELECT SEQ, JOB, PROC_SCHEMA, DEPENDENCY FROM "02"
UNION ALL
SELECT SEQ, JOB, PROC_SCHEMA, DEPENDENCY FROM "03"
UNION ALL
SELECT SEQ, JOB, PROC_SCHEMA, DEPENDENCY FROM "04"
UNION ALL
SELECT SEQ, JOB, PROC_SCHEMA, DEPENDENCY FROM "05"
UNION ALL
SELECT SEQ, JOB, PROC_SCHEMA, DEPENDENCY FROM "06";
-- Get the number of load layers
SELECT MAX(SEQ) INTO max_layer FROM JOBS;
-- Create task for logging start of FMC
SELECT JOB INTO var_job FROM JOBS WHERE SEQ = 0;
SELECT PROC_SCHEMA INTO proc_schema FROM JOBS WHERE SEQ = 0;
var_sql := ''CREATE OR REPLACE TASK EXEC_''||UPPER(var_job)||'' WAREHOUSE = ''||var_wh||'' AFTER EXEC_''||UPPER(dag_name)||'' AS
BEGIN
CALL ''||UPPER(proc_schema)||''.''||UPPER(var_job)||''(''''''||dag_name||'''''', TO_VARCHAR(SYSTEM$GET_PREDECESSOR_RETURN_VALUE()), TO_VARCHAR(CURRENT_TIMESTAMP::timestamp));
CALL SYSTEM$SET_RETURN_VALUE(SYSTEM$GET_PREDECESSOR_RETURN_VALUE());
END;'';
EXECUTE IMMEDIATE var_sql;
task_counter := task_counter + 1;
-- Create load tasks in order of dependency for all mappings after the initial mapping (>0).
-- The MAX() on SEQ is applied to insure procedures that span multiple layers run after all its dependent tasks have been created.
DECLARE j1 cursor for SELECT JOB, PROC_SCHEMA, MAX(SEQ) AS SEQ FROM JOBS WHERE SEQ > 0 GROUP BY JOB, PROC_SCHEMA ORDER BY SEQ;
BEGIN
FOR record in j1 do
var_proc := record.JOB;
proc_schema := record.PROC_SCHEMA;
var_seq := record.SEQ;
-- set task name; if it is last task in the dag add the dag name to the end logging procedure
task_name := CASE WHEN :var_seq = :max_layer THEN
''EXEC_''||UPPER(var_proc)||''_''||dag_name
ELSE
''EXEC_''||UPPER(var_proc)
END;
task_sql := ''CREATE OR REPLACE TASK ''||task_name||'' WAREHOUSE = ''||var_wh||'' AFTER '';
-- Build dependency list;
SELECT ARRAY_AGG(TO_ARRAY(DEPENDENCY)) INTO dep_arr FROM JOBS WHERE JOB = :var_proc;
dep_list := '''';
dep_counter := 0;
FOR dep in dep_arr DO
dep_counter := dep_counter + 1;
dep_list := dep_list||CASE WHEN :dep_counter > 1 THEN '', '' ELSE '''' END||''EXEC_''||UPPER(ARRAY_TO_STRING(dep,'', ''));
--Get the last dependency, ensuring only one dependency task is called to fetch the load cycle id.
dep_last_task := ''EXEC_''||UPPER(ARRAY_TO_STRING(dep,'', ''));
END FOR;
-- Build create task statements; the last layer is run without the handling procedure.
var_sql := CASE WHEN :var_seq = :max_layer THEN -- last task in DAG; SUCCESS
task_sql||dep_list||'' AS CALL ''||UPPER(proc_schema)||''.''||UPPER(var_proc)||''(TO_VARCHAR(SYSTEM$GET_PREDECESSOR_RETURN_VALUE(''''''||dep_last_task||'''''')), ''''1'''');''
ELSE -- all other tasks, run within handling procedure
task_sql||dep_list||'' AS BEGIN
CALL ''||UPPER(task_schema)||''.RUN_MAPPING_PROC(''''''||UPPER(proc_schema)||''.''||UPPER(var_proc)||''()'''', TO_VARCHAR(SYSTEM$GET_PREDECESSOR_RETURN_VALUE(''''''||dep_last_task||'''''')));
CALL SYSTEM$SET_RETURN_VALUE(SYSTEM$GET_PREDECESSOR_RETURN_VALUE(''''''||dep_last_task||''''''));
END;''
END;
EXECUTE IMMEDIATE var_sql;
task_counter := task_counter + 1;
END FOR;
END;
DROP TABLE JOBS;
-- Enable all tasks in the dag
SELECT SYSTEM$TASK_DEPENDENTS_ENABLE(''EXEC_''||:dag_name);
RETURN TO_VARCHAR(task_counter)||'' tasks created for dag ''''''||''EXEC_''||:dag_name||''''''.'';
END;
';The FMC Deployment and Transformation
After I set up my Snowflake objects, I downloaded my FMC zip file from VaultSpeed, unzipped it, and opened the mappings file. (Example: 268_mappings_INIT_SALES_20230706_063529.json.") To keep things simple for this example, I used an INSERT statement to load the JSON into the JSON_MAPPING table. I copied the JSON text to the statement below and ran the insert. Some handling was needed for the escape quotes (\") and where the source schema is qualified by the database name ("SNOWFLAKE_SAMPLE_DATA.") I removed these strings before copying and pasting the JSON.)
NOTE: This INSERT method is only for testing. Automatic Deployment will be used to insert the JSON in the full implementation.
TRUNCATE TASKER.TASK_MAPPING;
INSERT INTO TASKER.TASK_MAPPING (JSON_MAPPING)
SELECT TO_VARIANT(PARSE_JSON('{PASTE MAPPING JSON HERE}'));Once the JSON was loaded, I ran the main procedure "CREATE_VS_FMC()" with four parameters:
var_wh - the name of the Snowflake data warehouse
task_schema - the schema where you will create the tasks/DAG. I created all the tasks and objects in "TASKER".
dag_name - this is the basis for the name of the dag. The root task that identifies the dag will appear with the "EXEC_" prefix. In this example, The dag_name parameter was 'INIT_TPCH', and the root task that identifies the dag in Snowflake is 'EXEC_INIT_TPCH'. This corresponds to Name of the FMC in VaultSpeed.
load_sched - This is the load schedule. It is a required parameter and must be in the format that Snowflake specifies. I set my schedule to '60 MINUTE'. See task schedules in Snowflake docs for more details: https://docs.snowflake.com/en/sql-reference/sql/create-task.html
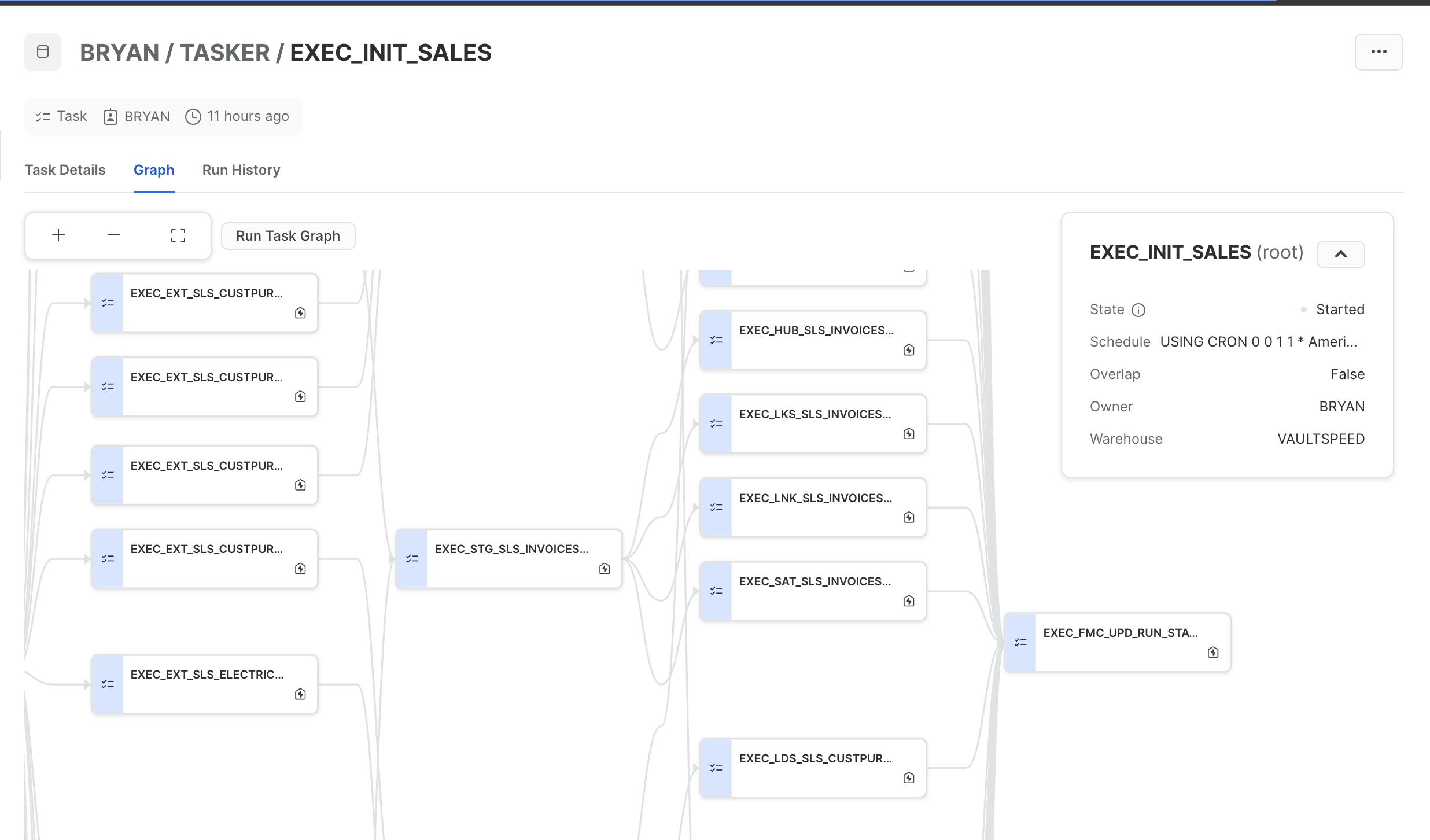
CALL TASKER.CREATE_VS_FMC('VAULTSPEED', 'TASKER', 'INIT_SALES', '60 MINUTE');A Snowflake DAG for My Data Vault!
Seventy-five new tasks appeared under Tasks in the schema “TASKER”. These made up the dag EXEC_INIT_SALES. I clicked on the root task by the same name and launched its detail page to see the graph view and execute the dag:
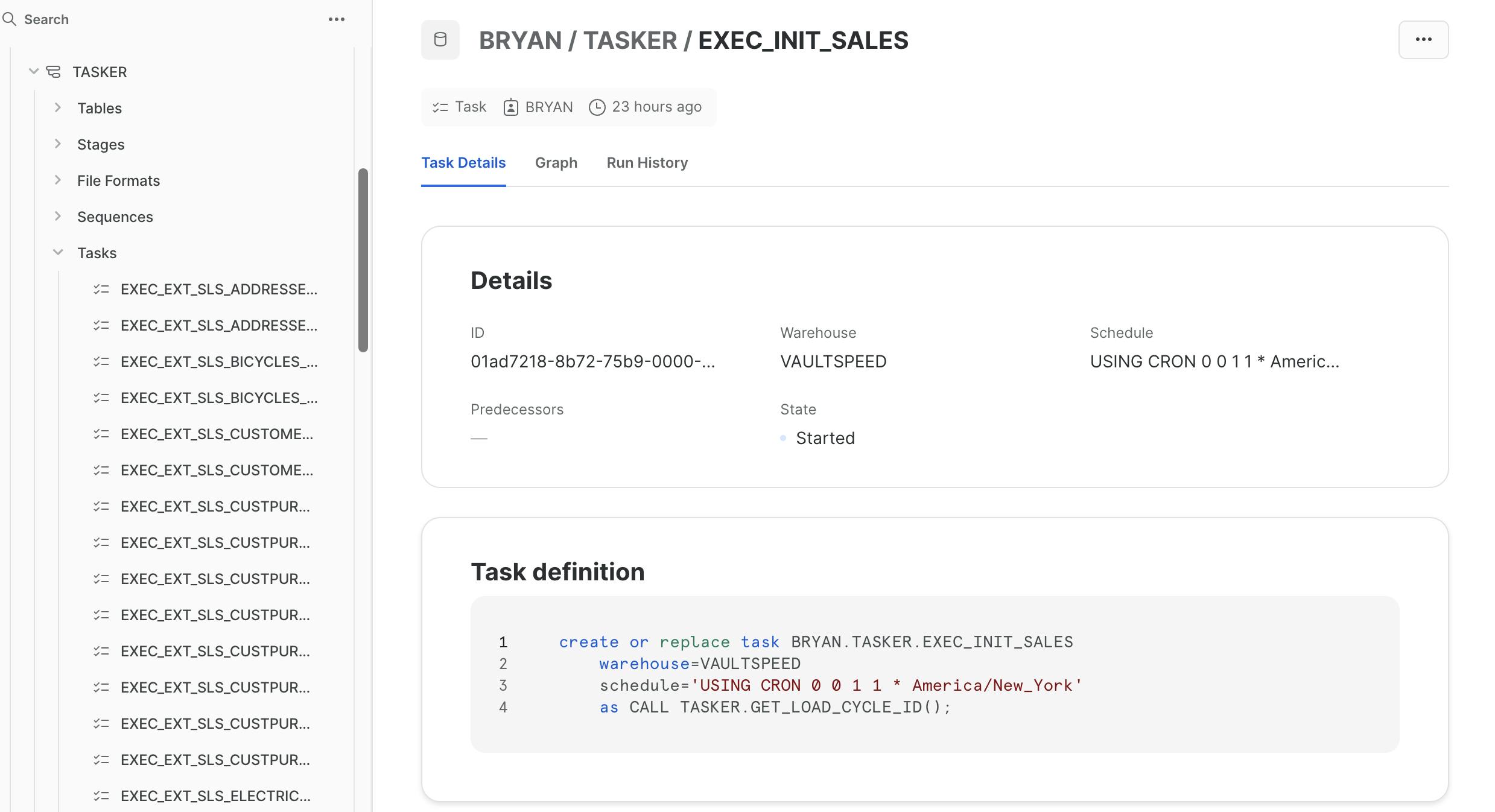
I saw my hubs, links, and satellites populated with data...
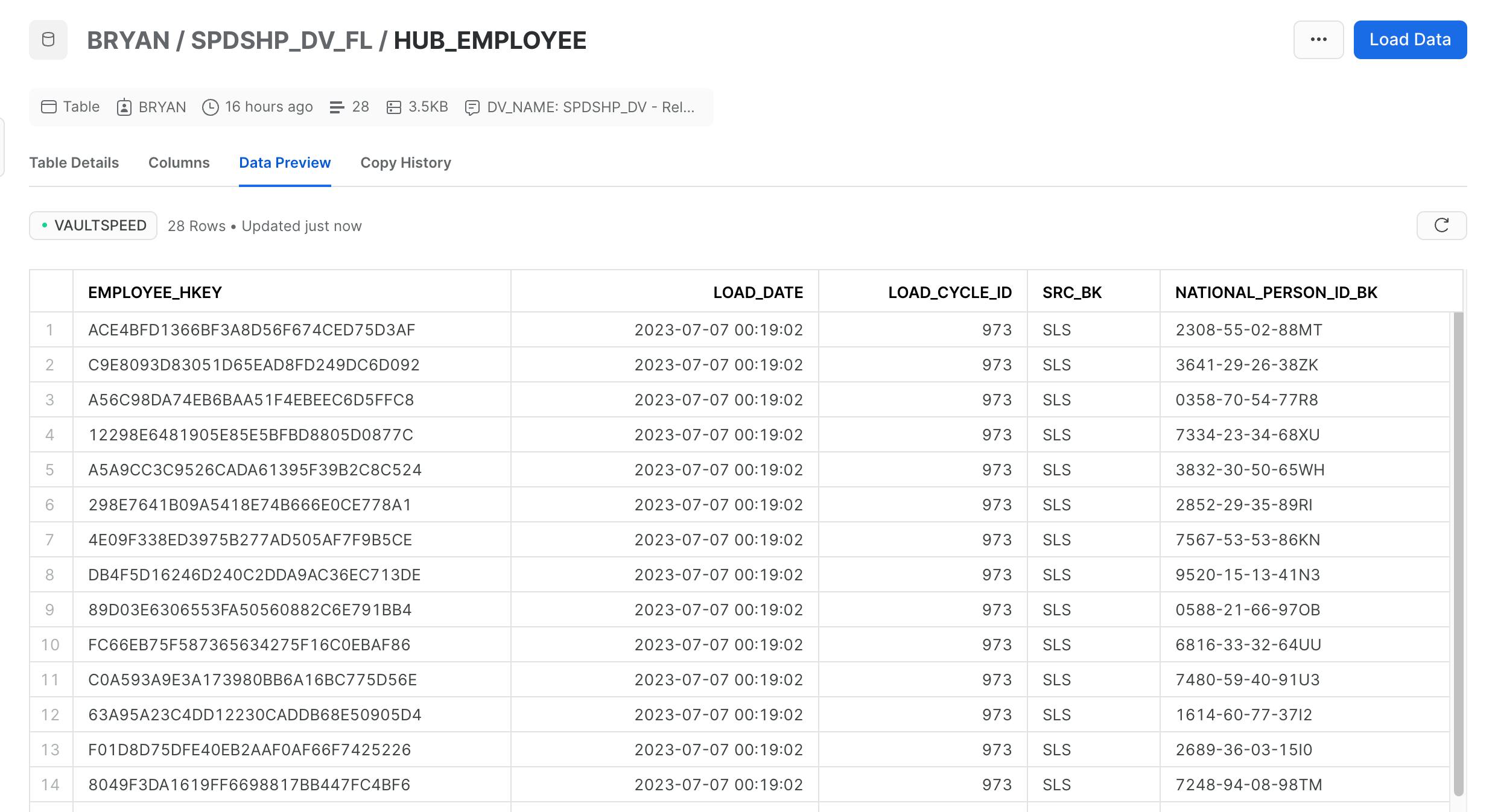
and my load control tables in the FMC schema were updated with load history:
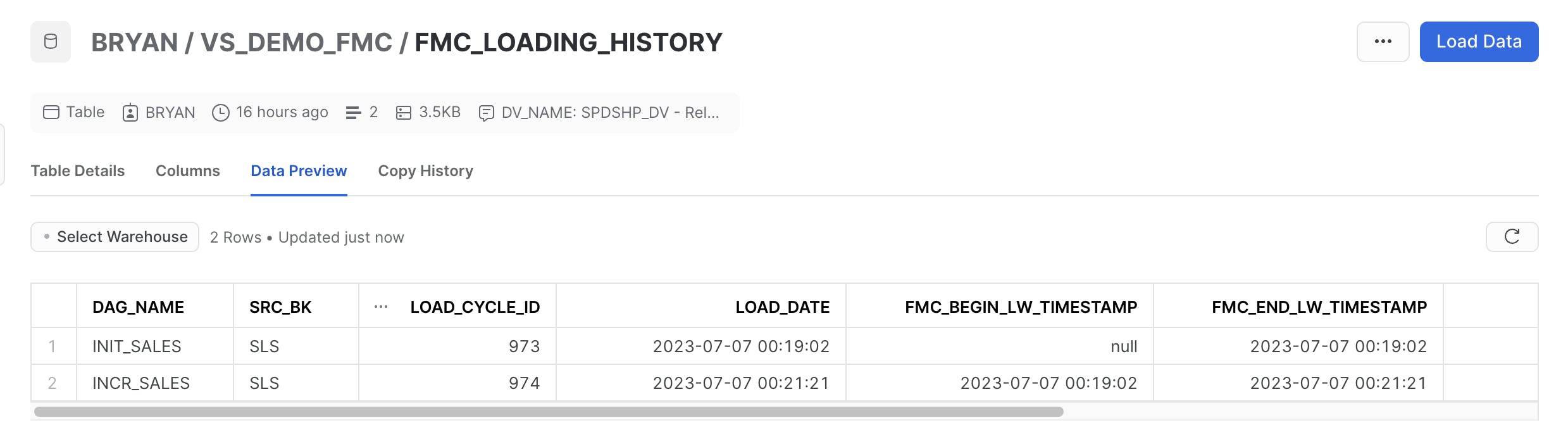
NOTE: There are limitations to the current release of Tasks in Snowflake. Read the Snowflake docs on Tasks to make sure this covers the scope and size of your data warehouse.
The Generic FMC takes advantage of native SQL that is now used to load the Data Vault tables and update the load control tables in each orchestration. These stored procedures and scripts make it possible to use the FMC in many different orchestration runtimes. This is one example on Snowflake. Hopefully, this has your gears turning, and you will find more ways to implement this flexible orchestration logic.
See A Snowflake DAG with the VaultSpeed Generic FMC, Part 2, for details on how to use Automatic Deployment to deploy your dags to Snowflake.