


I recently saw this video showcasing the lineage capabilities in Databricks:
https://www.youtube.com/watch?v=8wGUnXhISz0
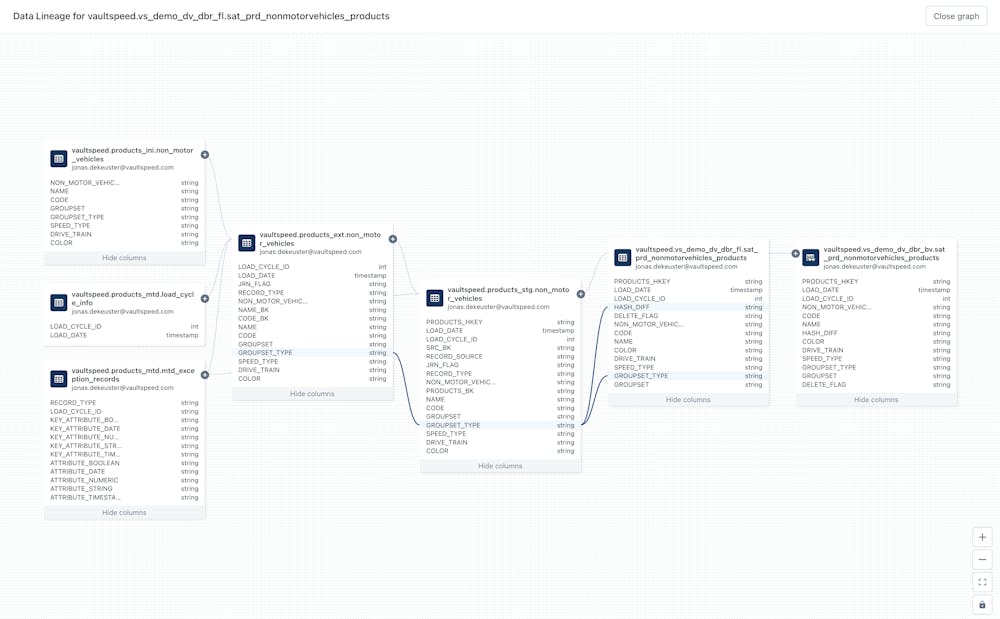
This triggered me to see how this applies to a data vault that has been deployed into Databricks. The result is pretty cool. Databricks automatically generates lineage based on all Databricks SQL notebooks that have been run for the last 30 days. It shows lineage down to the column level. So you can perfectly trace back how a column is being fed.
Prerequisites
A few prerequisites are to be met:
Your workspace has to be Unity Catalog enabled in the premium tier
Tables must be registered in Unity Catalog
You must be able to deploy your DDL code into the correct catalog (as described above). Unity uses a three-level namespace <catalog>.<schema>.<table> instead of a two-level namespace <schema>.<table>.
Deployment with VaultSpeed
Deploying into the right catalog can be achieved by using the latest Databricks drivers and setting a JDBC parameter ConnCatalog=<your_catalog>; in the JDBC connection string (you can find the default connection string in your Databricks cluster setup). Use JDBC Driver 2.6.20+
Making sure all your notebooks run in the right catalog can be achieved by setting a begin mapping command in your ETL settings: USE CATALOG <your_catalog>;

The lineage overview can be found in the last object screen tab. You can check which notebooks have interacted with the object.
